TDDで役立つIntelliJ IDEA機能
cleancodersの動画を見ていて気がついた、TDDに便利なIntelliJ IDEAの機能を5つご紹介します。
1. Live Template
TDDでは沢山のテストメソッドを書きます。毎回、「public void test ...」なんてタイプするのは面倒です。
そんなときに便利なのがLive Templateです。
例えば「test」と入力して「tab」を押します。

するとテストメソッドの雛形に変換されます。

「test」はデフォルトでは登録されていないので自分でIDEに登録する必要があります。
Preferences / Editor / Live Templates / otherで「+」ボタンを押します。下の画像を参考に必要な情報を入力してください。個人的にハマったのは一番下の「Applicable in」を選択し忘れたことです。

2. Show Context Actions
TDDでは存在しないクラスやメソッドをテストクラスで利用します。
例えば下のテストメソッドの例ではMyClassクラスがないのでIDEが赤字で警告を発しています。
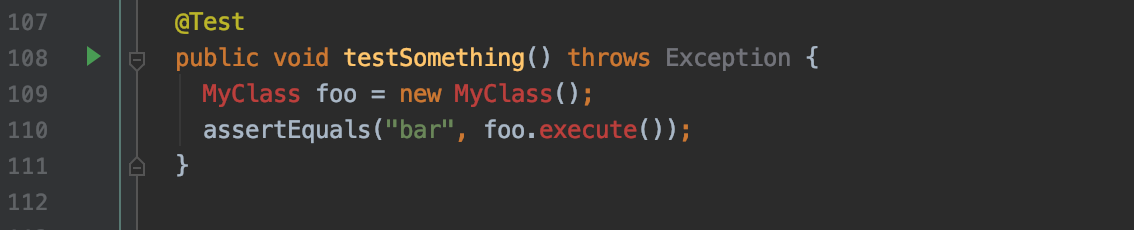
MyClassを作成してMyClass#executeを実装する必要があります。このとき便利なのがShow Context Actionsです。
警告が出ているMyClassにカーソルを合わせてoption + Enterと押すとエラーを解消するための選択肢が表示されます。「Create class 'MyClass'」を選べば簡単にMyClassクラスが作成できます。

同様に、executeメソッドにカーソルを合わせてoption + Enterから「Create method 'execute' in 'MyClass'」を選択すればMyClassクラスにexecuteメソッドのひな形を作ってくれます。

勿論、普通にMyClass.javaファイルを作成してMyClassクラスとexecuteメソッドを書くこともできます。でも書いたテストメソッドから直接、option + Enterで次の作業に移動する方がTDDとしてリズムがよいと感じます。
3. テストの再実行
TDDでは頻繁にテストを実行します。その度にマウス操作していてはリズムが悪くなります。
Ctrl + rで前回実行したテストを再実行できます。
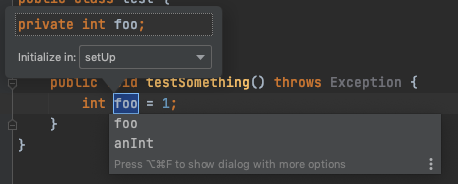
4. Introduce Field
複数のテストを記述していく中でテスト間で重複処理が発生します。こうした部分はsetUpなどに移して重複を排除します。
TDDでは先にRefactorしてはいけないので重複が発生するとわかっていても最初からsetUpを書くことはできません。このため発生した重複をsetUpへ移す作業は頻繁に発生します。
変数をフィールドにしてsetUpに移すときに便利なのが「Introduce Field」。option + Command + Fです。
右クリック、Refactorからもできますが頻繁に発生するのでショートカットの方が断然、効率がよいです。
5. Run with Coverage
ある程度、実装が進むと気になるのがCoverageです。テストクラスを右クリックして「Run <テストクラス> with Coverage」を選択することで簡単に確認することができます。

テストが完了するとCoverageが以下のようにクラス名の隣に表示されます。StackクラスはInterfaceなのでCoverageが表示されません。BoundStackクラスのCoverageは低いですね。

カバーされなかったコードを確認してみましょう。エディタでBoundStackクラスを開くとカバーされた行は緑、カバーされなかった行は赤が表示されます。

リファクタリングで作成したNull Objectのテストに漏れがあったことがわかりました。
cleancodersのStack Kataを見て感じたことのまとめ
前回、cleancodersのStack Kataのビデオに個人的な解説を付けました。
しかし35分のビデオに詳細な解説を付けたので長文になってしまい要点が読み取れません。
そこでこの記事では要点のみをまとめます。
私の個人的な理解なので合っているとは限りません。正解が知りたい人はcleancoders.comのAdvanced TDDというシリーズで勉強してください。動画は有料です。
Redですること
- 原則としてもっとも原始的(degenerate)で周辺的(peripheral)な試験から行う。
- この原則からどのように実践に落とし込むかについては説明が理解できておらず、現時点では自分の中で2つの仮説がある。
仮説1:Stack Kataの手順から推測
・最初の試験の選び方
- 空のオブジェクトで試験できることから試験する。
- 核心機能の周辺的な確認に必要な機能から試験する。
- 周辺機能の最も原始的なパターンから試験する。
・その後の試験の選び方
- 核心機能の試験に必要な周辺機能の試験
- この中で核心機能の周辺的な部分が実装されることがある
- 核心機能
- 核心機能がないと試験できない周辺機能
・各試験は空→単数→複数→エラーの順で実施する
- 空ケースでエラーが発生する場合は単数ケースから始める
- 単数ケースで複数ケースに対応できるコードができた場合、複数ケースの試験はスキップする
仮説2:Stack Kataのコメントから推測
以下の順に実施する
- 空オブジェクトで試験できること
- 核心機能の周辺部分
- 核心機能の核心部分
- 核心機能を利用する周辺機能
Greenですること
Compile Error発生時
- Compile Errorが出ていればCompile Errorを消すための最小限の実装を行う。
- 具体的には空のクラス、空のメソッド、空のフィールドなどを作成する。
- メソッドのSignatureを変えることもある。
- なにかreturnする必要があるときはAssertion Errorが出るものを返す。(null, -1など)
- 目標はCompile Errorが消えてAssertion Errorが出ること。
Assertion Error発生時
- Assertion Errorが出ている場合はAssertion Errorを消すための最小限の実装を行う。
- このとき最も汎用的でない方法(以下参照)で解決することを目指す。
1. まずは空で実装。
2. 次は単数で実装。
- マジックナンバー
- 計算
- 変数
- 分岐
3. 次は複数に対応する。
- 配列
- Collection
- while
- recursive
- for
4. なるべく避けたい手を使う
- 代入
- if/else文、switch文
5. きれいにする
- 重複除去
Blueですること
- 重複があれば取り除く。
- assertの中がごちゃごちゃしていればすっきりさせる。
- Testもコードであることを意識する。
その他
- 試験と実装を繰り返す中でコードは汎用的になり、テストコードは具象的になる。
cleancodersのStack Kataに解説を付けた
cleancoders.comというサイトのプログラミング動画を見て勉強しています。 その中で「Stack Kata」という、StackクラスをTDDで作成するビデオがあります。このビデオは無料で公開されています。
https://cleancoders.com/episode/clean-code-episode-4-sc-1-stack
このビデオの中にもある程度の解説はあるのですが、TDD初心者にとっては早すぎてついていけません。
そこで自分の理解をもとに解説を付けてみました。35分の動画に対する詳細解説なのでかなりの長文です。「私個人の理解」なので合っているとは限りませんが、もし同じビデオで勉強している人がいれば参考にしてみてください。
正解が知りたい人はcleancoders.comのAdvanced TDDというシリーズで勉強してください。こちらの動画は有料です。(そして私に教えてください)
テストクラス作成
試験名:nothing
最初にテストクラスを作成して環境の動作確認を行う。
Stackクラスを作成する予定なのでStackTestクラスを作成する。 クラス名をTestStackとしなかったのはUncle Bobの好みと思われる。 想像するにテストコードとコードを同じpackageに配置したとき、StackクラスとStackTestクラスがアルファベット順にソートされて上下に並んで表示されることを期待しているのだろう。 テストコード用の別ディレクトリにテストコードを配置する場合はこの命名規則は意味がない。
package名は仮にstackとする。 気に入らなければ後で移動する。
StackTest#nothingを作成する。 @Testのためにjunitをimportする。 実行してテスト環境が整っていることを確認する。
package stack;
import org.junit.*;
public class StackTest {
@Test
public void nothing() throws Exception {
}
無事、確認ができたらStackTest#nothingは削除する。
空のStackオブジェクトを作成する
試験名:createStack
Red
Stackクラスを作りたい。 しかしTDDでは先に試験をしなくてはコードは書けない。 Stackクラスを作成する試験として、Stackオブジェクトを作成する試験を実施する。
StackTest#createStackを作成する。 既存のStackクラスと衝突するので最初はMyStackクラスと命名する。
package stack;
import org.junit.*;
public class StackTest {
@Test
public void createStack() throws Exception {
Stack stack = new Stack()
}
Green
compile error
MyStackクラスがないのでIDEが警告を出す。 コンパイラを通すためにMyStackクラスを作成する。 実装はコンパイラを通す最小限のものに留めたいのでMyStackの中身は空にする。 StackTest#createStackに戻ってMyStackをStackにRenameする。 テストを実行してPassすることを確認する。
package stack;
public class Stack {
}
空のStackオブジェクトが空なことを確認する1
試験名:createStack -> newlyCreateStack_ShouldBeEmpty
Red
createStackは現時点でなにもAssertしていない。次にStackが空であることの確認を行うが、なぜこの試験を選んだのか、考え方が不明。仮説を以下に上げる。
・考え方1
複数より単数、単数より空の方が原始的。 空オブジェクトで試験できることを考える。 Stackが空であることの確認から行う。
・考え方2
最も周辺的(peripheral)な機能に対して最も原始的(degenerate)な確認を行うこととする。 push/popなどの核心機能は後回しにしたい。 topやfindも核心機能がないと試験できないので後回しにしたい。 isEmptyやgetSizeは核心部分が不在でも試験できる。
・考え方3
push/popの周辺的な部分を試験するにはまずはサイズを確認する機能が必要だ。 「値を格納する、取り出す」という核心部分は基本的な構造が見えてからにしたい。 そこでサイズ確認から行うこととする。
この試験の中でオブジェクトを作成するためcreateStackは不要となる。 よってcreateStackは削除する。 後々、削除することがわかっている試験を作成するのはTDDではよくある。
Assert.assertTrueのためにorg.junit.Assert.*をstatic importする。 名前をStack#newlyCreateStack_ShouldBeEmptyに変更する
@Test
public void newlyCreateStack_ShouldBeEmpty() throws Exception {
Stack stack = new Stack()
assertTrue(stack.isEmpty());
}
Green
compile error
Stack#isEmptyがないのでコンパイルエラーが出る。 コンパイラを通すためにStack#isEmptyをGetterとして作成する。 実装は最小限に留めたいのでemptyは初期化しない(= false) 実行してAssertion ErrorでFailすることを確認する。
package stack;
public class Stack {
private boolean empty;
public boolean isEmpty() {
return empty;
}
}
assertion error
Assertion Errorを解決するために必要最小限の変更を行う。 emptyをtrueで初期化する。 実行してPassすることを確認する。
private boolean empty = true;
Stackクラスの最終形を考えるとtrueというリテラルを書くのは間違っている。 サイズを管理するフィールドを作成してそのサイズから真偽値を判定すべき。 しかしそれはTDDではやりすぎ。 GreenではTestをPassさせるための最小限、かつもっとも非汎用的な実装を行うことが求められる。 突然、汎化されたコードを作成するとTestが書かれていないパターンが発生し、それらを後追いで書くことになってしまう。 後々、Stuckする可能性や最適でないアルゴリズムが生まれる可能性も高くなる。 今回のテストは変数、計算、分岐など汎用的実装を導入する前に、リテラル/定数でPassできる。 TDDではリテラル/定数でPassさせるのが正しい。
空のStackオブジェクトが空なことを確認する2
試験名:newlyCreateStack_ShouldBeEmpty
Red
サイズを確認するgetSizeメソッドも必要だ。 まずはもっとも原始的な空オブジェクトで試験をする。 newlyCreateStack_ShouldBeEmptyと実質、同じ試験なので同じテストに含める。 実質、同じ試験なのでSingle Assertion Ruleの違反ではない。
@Test
public void newlyCreateStack_ShouldBeEmpty() throws Exception {
assertTrue(stack.isEmpty());
assertEquals(0, stack.getSize());
}
Green
compile error
コンパイラを通すためにStack#getSizeをGetterとして作成する。 実装は最小限に留めたいのでsizeは初期化しない(= 0) 実行してPassすることを確認する。
1回Pushするとサイズが1になることを確認
試験名:AfterOnePush_StackSizeShouldBeOne
Red
この試験を選んだ考え方も不明。仮説を示す。
・考え方1
核心機能の周辺的な確認を行う準備が整ったのでpush/popの周辺部分の試験を行う。 「値を格納/取り出す」はpush/popの核心部分なので後回し。 push/popしてサイズが変わるかを単数から確認する。
・考え方2
空ケースが完了したので次に原始的な単数ケースへ進む。 Stackのサイズを1増減させるにはpush/popが必要だ。 よってこの試験は核心機能(push, pop)の最も周辺部分の試験という意味合いもある。
pushできないとpopの試験ができないためpushの単数から着手する。
StackTest#AfterOnePush_StackSizeShouldBeOneを作成する Stack stack = new Stack()が重複しているがまだリファクタしない。 Greenが終了してからリファクタする。
@Test
public void AfterOnePush_StackSizeShouldBeOne() throws Exception {
Stack stack = new Stack()
stack.push(1);
assertEquals(1, stack.getSize());
}
Green
compile error
コンパイラを通すためにStack#pushを作成する。 実装は最小限に留めたいのでpushの中身は空。 実行してAssertion ErrorでFailすることを確認する。
public void push(int element) {
}
assertion error
Stack#pushでsize++する。 実行してPassすることを確認する。
public void push(int element) {
size++;
}
Red
空ではないことも追加で確認する。 論理的には同じテストなのでSingle Assertion Ruleの違反ではない。
@Test
public void AfterOnePush_StackSizeShouldBeOne() throws Exception {
Stack stack = new Stack()
stack.push(1);
assertEquals(1, stack.getSize());
assertFalse(stack.isEmpty());
}
実行してassertion errorでFailすることを確認する。
Green
assertion error
sizeを1で初期化すると以前のテストがFailしてしまう。 リテラル/定数でPassさせることは限界。 試験の具象度が1段上がっているので、コード汎化度も上げて、計算で対応することを考える。
Stack#isEmptyを修正。 sizeが1でなければfalseを返すようにする。 戻り値はBooleanなのでif/elseや三項演算子ではなくシンプルにreturn + <評価式>とする
public boolean isEmpty() {
return size == 0;
}
emptyフィールドが不要になったので削除する。 不要になったものを削除することはリファクタリングではない。
実行してPassすることを確認する。 これでisEmptyが汎用的になった。
Blue
テストコードの重複をリファクタする。 stackをフィールドにしてsetUpメソッドで初期化する。 各テストメソッド内からオブジェクト作成コードを削除する。
@Before
public void setUp() throws Exception {
stack = new Stack();
}
実行してPassすることを確認する。
1回Popすると空になることを確認
試験名:afterOnePushAndOnePop_ShouldBeEmpty
Red
pushの単数ケースが完了した時点でコードは既に複数ケースに対応できる。 よってpushの複数ケースの試験はスキップする。 次はpopの単数に着手する。
StackTest#afterOnePushAndOnePop_ShouldBeEmptyを作成する。 確認はisEmtpyのみ。getSizeもisEmptyもsizeフィールドに依存しているので結果は同じになる。
@Test
public void afterOnePushAndOnePop_ShouldBeEmpty() throws Exception {
stack.push(1);
stack.pop();
assertTrue(stack.isEmpty());
}
Green
compile error
コンパイラを通すためにStack#popを作成する。 実装は最小限に留めたいのでpopの中身は空。 popは最終的に整数(intかInteger)を返すはずだがこの時点では不要なので型はvoidにする。 実行してAssertion ErrorでFailすることを確認する。
assertion error
Stack#popでsizeを減算させる。 実行してPassすることを確認する。
public void pop() {
size--;
}
Uncle Bobが--sizeにしている。 これはStackの一番上のデータを返すpopの最終的な挙動を想像して、一番上のデータ位置を表すsize - 1にしたと思われる。
Overflowのエラー処理を確認する
試験名:WhenPushedPastLimit_StackOverflows
Blue
popのコードは既に複数ケースに対応できているので複数ケースの試験はスキップする。
周辺部分(サイズの増減と確認)は動いてきた。 当該周辺部分のエラー処理を試験する。 まずは上限超過の試験を行う。
pushのエラーはOverflowなのでOverflowの試験をする。 複数回、PushしてLimitを超過させたい。 そのためにはStackにLimitが必要。
Limitはインスタンス作成時に設定する。 コンストラクタに渡してもよいが、後々、Special Case Patternを使いたいのでmakeファクトリメソッドを使う。
まずはファクトリメソッドを実装してsetUpを置き換える。 コンストラクタはprivateにする。中身は空。
public static Stack make(int capacity) {
return new Stack(2);
}
private Stack(int capacity) {
}
Red
OverflowのExceptionクラスはStackクラスの内部クラスとする。 ExceptionのFQCNでなんのエラーかわかる。 実行してFailすることを確認する。
@Test(expected = Stack.Overflow.class)
public void WhenPushedPastLimit_StackOverflows() throws Exception {
stack.push(1);
stack.push(1);
stack.push(1);
}
Green
compile error
ExceptionはRuntimeExceptionを継承する。 Checked Exceptionはreverse dependencyが発生するので使わない。 ある子クラスで新しいExceptionをthrowするとBaseクラスの変更が必要になり全ての子クラスが影響を受けてしまう。
public class Overflow extends RuntimeException{
}
assertion error
空、マジックナンバー、計算では対応できない。 Stack#pushでsizeとcapacityを比較を比較するしかない。 汎化度を上げてif文を使う。
capacityをフィールドにする。 Stack#pushでsizeとcapacityを比較して、Limit超過時にはExceptionを投げるようにする。 実行してPassすることを確認する。
private int capacity;
private Stack(int capacity) {
this.capacity = capacity;
}
public void push(int element) {
if (size == capacity)
throw new Overflow();
size++;
}
Underflowのエラー処理を確認する
試験名:WhenEmptyStackIsPopped_ShouldThrowUnderflow
Red
同様に下限超過の試験を作成する。
pop1回でUnderflowが発生する。
@Test(expected = Stack.Underflow.class)
public void WhenEmptyStackIsPopped_ShouldThrowUnderflow() throws Exception {
stack.pop();
Green
compile error
Underflowクラスを同様に実装する。 実行してFailすることを確認する。
public class Underflow extends RuntimeException{
}
assertion error
空、マジックナンバー、計算では対応できない。 Stack#popでsizeを確認するように変更する。 実行してPassすることを確認する。
public void pop() {
if (size == 0)
throw new Underflow();
size--;
}
pushしたものをpopできることを確認する
試験名:WhenOneIsPushed_OneIsPopped
Red
周辺部分の単数ケース、複数ケース、エラーが完了した。 Stackの核心部分(値を入れる、取り出す)を試験する準備が整った。 まずは単数ケースから始める。 pushとpopが互いの動作に依存するので一緒に試験する。 つまり1つpushしてpopする。
StackTest#WhenOneIsPushed_OneIsPoppedを作成する。
@Test
public void WhenOneIsPushed_OneIsPopped() throws Exception {
stack.push(1);
assertEquals(1, stack.pop());
}
Green
compile error
コンパイラを通すためにStack#popをint型にし、return -1を返すようにする。 -1を返すのは意図的にAssertion ErrorでFailさせたいから。nullやfalseと同じ。 コンパイラエラーが消えたら実行してAssertion ErrorでFailすることを確認する。
public int pop() {
if (size == 0)
throw new Underflow();
size--;
return -1;
}
assertion error
Stack#popがint型のelementフィールドを返すようにする。 Stack#pushがint型のelementフィールドに引数elementを代入するようにする。 この時点では配列やCollectionはまだ使わない。 実行してPassすることを確認する。
private int element;
public void push(int element) {
if (size == capacity)
throw new Overflow();
this.element = element;
size++;
}
public int pop() {
if (size == 0)
throw new Underflow();
size--;
return element;
}
2つpushしたら2つpopできることを確認
試験名:WhenOneAndTwoArePushed_TwoAndOneArePopped
Red
単数ケースが成功したので複数ケースを試験する。
StackTest#WhenOneAndTwoArePushed_TwoAndOneArePoppedを作成する。 実行してFailすることを確認する。
@Test
public void WhenOneAndTwoArePushed_TwoAndOneArePopped() throws Exception {
stack.push(1);
stack.push(2);
assertEquals(2, stack.pop());
assertEquals(1, stack.pop());
}
Green
assertion error
変数でも分岐でも対応できないので配列を導入する。
elementをint型配列elementsに変える。 Stack#pushでelements[size]に格納するよう変更する。 Stack#popでelements[--size]を返すように変更する。 実行してPassすることを確認する。
private int elements[];
private Stack(int capacity) {
this.capacity = capacity;
elements = new int[capacity];
}
public void push(int element) {
if (size == capacity)
throw new Overflow();
this.elements[size++] = element;
}
public int pop() {
if (size == 0)
throw new Underflow();
return elements[--size];
capacityが負の整数のときのエラー処理を確認する
試験名:WhenCreatingStackWithNegativeSize_ShouldThrowIllegalCapacity
Red
核心機能のエラーについて考える。 配列を導入したので負の整数をcapacityに指定されるとエラーが発生する可能性がある。 負の整数をcapacityに指定された場合のエラー処理の試験を行う。
実行してFailすることを確認する。
@Test(expected = Stack.IllegalCapacity.class)
public void WhenCreatingStackWithNegativeSize_ShouldThrowIllegalCapacity() throws Exception {
Stack.make(-1);
}
Green
compile errorr
public class IllegalCapacity extends RuntimeException {
}
assertion error
makeファクトリメソッドでcapacityのチェックをする。 コンストラクタでcapacityのチェックをすると無駄なcallが発生する。
makeファクトリメソッドはstaticなのでIllegalCapacityもstaticにする。 実行してPassすることを確認する。
public static Stack make(int capacity) {
if (capacity < 0)
throw new IllegalCapacity();
return new Stack(2);
}
public static class IllegalCapacity extends RuntimeException {
}
Uncle Bobは中身が1行のif文には{}をつけない。 是非について賛否がわかれそうだが、これはコードの表示をコンパクトにしたいということとif文の中身を1行に収めることを推奨するためのPracticeと思われる。
capacityが0のときの挙動を確認する
試験名:WhenCreatingStackWithZeroCapacity_AnyPushShouldOverflow
Red
引き続きエラーについて考慮する。 capacity=0を指定された場合、どのように振る舞うべきか考える。 サイズ0のStackの作成は許容されるべきで、サイズ0のStackとして振る舞う。 ただしSpecial Case Patternで効率よく動作させたい。
StackTest#WhenCreatingStackWithZeroCapacity_AnyPushShouldOverflowを作成する。
@Test(expected = Stack.Overflow.class)
public void WhenCreatingStackWithZeroCapacity_AnyPushShouldOverflow() throws Exception {
stack = Stack.make(0);
stack.push(1);
}
Green
実行してPassすることを確認する。
Blue
// Special Case PatternでRefactorする
外部から見た振る舞いは正しい。 ただ0のスタックなのにリソースを確保したりしている点がおかしい。 Refactoringする。
StackからInterfaceをExtractする。makeメソッドは除く。 元のStackクラスはBoundedStackという名前にする。 @overrideアノテーションは使わない。 IDEだとエディタ画面左端のアイコンでOverrideされていることがわかるからだろう。 実行してPassすることを確認する。
package stack;
public interface Stack {
boolean isEmpty();
int getSize();
void push(int element);
int pop();
public static class IllegalCapacity extends RuntimeException {
}
}
BoudedStack#makeで中で、capacity=0のときStackから無名クラスを作成する。 コンパイラを通すためにOverflowとUnderflowをstaticにする。
public static Stack make(int capacity) {
if (capacity < 0)
throw new IllegalCapacity();
if (capacity == 0)
return new Stack() {
public boolean isEmpty() {
return true;
}
public int getSize() {
return 0;
}
public void push(int element) {
throw new Overflow();
}
public int pop() {
throw new Underflow();
}
};
return new BoundedStack(capacity);
}
無名クラスをMoveしてprivate innter static classにする。 実行してPassすることを確認する。
public static Stack make(int capacity) {
if (capacity < 0)
throw new IllegalCapacity();
if (capacity == 0)
return new ZeroCapacityStack();
return new BoundedStack(capacity);
}
private static class ZeroCapacityStack implements Stack {
public boolean isEmpty() {
return true;
}
public int getSize() {
return 0;
}
public void push(int element) {
throw new Overflow();
}
public int pop() {
throw new Underflow();
}
}
これがSpecial Case Pattern。このためにファクトリメソッドを作成した。
1回pushしてtopできることを確認する
試験名:whenOneIsPushed_OneIsOnTop
Red
核心機能が完了した。 次は核心機能がないと試験できなかった機能を試験する。 topとfindならtopの方が周辺的なのでtopから試験する。 空ケースはエラーが発生するので後に回す。 まずは単数ケースの試験を行う。
StackTest@whenOneIsPushed_OneIsOnTopを作成する。
@Test
public void whenOneIsPushed_OneIsOnTop() throws Exception {
stack.push(1);
assertEquals(1, stack.top());
}
Green
compile & assertion error
topをStack Interface、BoundedStack、ZeroCapacityStackに実装する。 ZeroCapacityStackでは-1を返す。最終的になにを返すかは今後、空でtopしたときのエラー試験で考える。 実行してPassすることを確認する。
public int top() {
return elements[size-1];
}
ここではcompile errorとassertion erorの両方を一度に解決している。 実装がシンプルな場合はわざとassertion errorを起こすことはしないようだ。
空のStackでtopするときのエラーの確認
試験名:WhenStackIsEmpty_TopThrowsEmpty
Red
複数ケースに対応できるコードができたので複数ケースの試験はスキップしてエラーについて考慮する。 空のStackをtopしたケースを試験する。 加えて言うとZeroCapcityStack#topの挙動を決めるために空Stackをtopしたときの動作について考える必要がある。
StackTest#WhenStackIsEmpty_TopThrowsEmptyを作成する。
@Test(expected = Stack.Empty.class)
public void WhenStackIsEmpty_TopThrowsEmpty() throws Exception {
stack.top();
}
Green
compile error
Stack InterfaceにEmptyクラスを作成する。staticにする。 実行してFailすることを確認する。
public static class Empty extends RuntimeException {
}
assertion error
BoundedStack#topで空ならEmptyをThrowさせる BoundedStack#popのif文の判定もisEmptyにRefactorしたいがPassするまで後回しにする。 実行してPassすることを確認する。
public int top() {
if (isEmpty())
throw new Empty();
return elements[size-1];
}
Blue
BoundedStack#popのif文の判定もisEmptyに変える
public int pop() {
if (isEmpty())
throw new Underflow();
return elements[--size];
}
ZeroCapcityStack#topでもEmptyを投げる これはRefactorではないのでRed/Gree/BlueのRuleに違反していると思う。 実装を忘れないように?ZeroCapcityStackは核心機能ではないから?
public int top() {
throw new Empty();
}
ZeroCapacityStackの試験をする。
試験名:WithZeroCapcityStack_TopThrowsEmpty
Red & Green
試験が後追いになっているがStackTest#WithZeroCapcityStack_TopThrowsEmptyを作成する。 実行してPassすることを確認する。
@Test(expected = Stack.Empty.class)
public void WithZeroCapcityStack_TopThrowsEmpty() throws Exception {
stack = BoundedStack.make(0);
stack.top();
}
Blue
// ExceptionをStack Interfaceへ移動する
BoundedStackのOverflowとUnderflowをPull members upでInterfaceへ移動する Uncle Bobはこの後、なぜか試験をしていない。
findの動作を確認する
試験名:GivenStackWithOneTwoPushed_FindOneAndTwo
Red
topが完成したのでfindメソッドを試験する。
findメソッドはtopからのindexを返す。 StackTest#GivenStackWithOneTwoPushed_FindOneAndTwoを作成する。 まずは2つ数字を入れて最初の数字のindexが1になることを確認する。 degenerateという意味では1つだけ数字を入れるのでは? 配列にした時点で1つにこだわる必要はないのか? 一緒に2つ数字を入れて2番めの数字のindexが0になることを確認する。 Logicalには1つの試験なので複数Assertを入れてる Act/Assert/Act/AssertではないのでSingle Assertion Ruleの違反ではない。
@Test
public void GivenStackWithOneTwoPushed_FindOneAndTwo() throws Exception {
stack.push(1);
stack.push(2);
assertEquals(1, stack.find(1));
assertEquals(0, stack.find(2));
}
Green
compile error
findをStack Interfaceで定義する。 実行してcompile errorでFailすることを確認する。
int find(int element);
BoundedStack#findを実装する。 compile errorを解消してassertion errorを出すことが目的なので-1を返す。 実行してcompile errorでFailすることを確認する。
public int find(int element) {
return -1;
}
ZeroCapacityStack#findを実装する。 実行してFailすることを確認する。 今度はAssertion Errorで失敗する。
public int find(int element) {
return -1;
}
assertion error
BoundedStack#findを実装する。 見つからなかったときのreturn -1は仮。最終的な挙動は今後、見つからなかったときの試験で検討、実装する。 実行してPassすることを確認する。
public int find(int element) {
for (int i = size-1; i >= 0; i--)
if (elements[i] == element)
return (size - 1) - i;
return -1;
}
findで見つからなかったときの挙動を確認
試験名:GivenStackWithNo2_Find2ShouldReturnNull
Red
findで見つかったときの挙動は試験できた。 次は見つからなかったときの挙動を試験する 見つからないときはNullを返す
実行するとコンパイルエラーが発生する。
@Test
public void GivenStackWithNo2_Find2ShouldReturnNull() throws Exception {
assertNull(stack.find(2));
}
Green
compile error + assertion error
BoundedStack#findとZeroCapacityStack#findのSignitureをIntegerに変え、nullを返す。 Stack#findのSignitureもIntegerに変える。
public Integer find(int element) {
for (int i = size-1; i >= 0; i--)
if (elements[i] == element)
return (size - 1) - i;
return null;
}
実行するとGivenStackWithOneTwoPushed_FindOneAndTwoでコンパイルエラーが発生する。 GivenStackWithOneTwoPushed_FindOneAndTwoを変更してPassすることを確認する。
@Test
public void GivenStackWithOneTwoPushed_FindOneAndTwo() throws Exception {
stack.push(1);
stack.push(2);
assertEquals(new Integer(1), stack.find(1));
assertEquals(new Integer(0), stack.find(2));
}
Blue
GivenStackWithOneTwoPushed_FindOneAndTwoがあまり見やすくない。 assertの中がごちゃごちゃしていて読みにくい。 Refactorする。
@Test
public void GivenStackWithOneTwoPushed_FindOneAndTwo() throws Exception {
stack.push(1);
stack.push(2);
assertEquals(new Integer(1), stack.find(1));
assertEquals(new Integer(0), stack.find(2));
}
Passすることを確認する。 まだ見にくい。
@Test
public void GivenStackWithOneTwoPushed_FindOneAndTwo() throws Exception {
stack.push(1);
stack.push(2);
assertEquals(1, stack.find(1).intValue());
assertEquals(0, stack.find(2).intValue());
}
Passすることを確認する。 まだ見にくい。
Inlineだと汚いのでやめる。 Refactor -> Introduce Variableで外に出す。 Shift + Cmd + ↑でStatementの順序を揃える。 Passすることを確認する。
@Test
public void GivenStackWithOneTwoPushed_FindOneAndTwo() throws Exception {
stack.push(1);
stack.push(2);
int oneIndex = stack.find(1);
int twoIndex = stack.find(2);
assertEquals(1, oneIndex);
assertEquals(0, twoIndex);
}
mixinとは
Pythonなどのコードを見ているとよく見かける「mixin」。
今までは雰囲気でさらりと流してましたが今回、調べてみました。
mixinとは
主に多重継承が可能な言語で使われる継承の使い方です。
継承とは本来、親クラスとその子クラスの間に特別な階層関係を発生させる機能です。
しかしmixinではコードの再利用のための手段として継承を使います。mixinクラスで実装した機能は子クラスにも具備されますが2つのクラスの間にis-a関係が成立するとは限りません。mixinクラスは「親」というより便利機能を具備した「ユーティリティ」という扱いです。いくつものmixinクラスを継承させれば複数の機能を持つ子クラスを簡単に作成できます。
多重継承ではインスタンス変数が重複すると面倒なことになります。これを避けるため、多重継承が前提のmixinクラスにはインスタンス変数を持たせないことが一般的です。
主な使い方
主な使い方を挙げます。
- 複数のクラスにまたがる横断的な機能をmixinクラスで実装して各クラスにmixinする
- あるクラスが持ちうる様々な役割・機能をmixinクラスで実装して、mixinクラスの組み合わせによって様々なフレーバーのクラスを作る
- mixinクラスをTemplate MethodパターンのAbstractクラスにして、固有の処理はmixinされたクラスで実装する
Python以外の言語におけるmixinの実装
多重継承ができないJavaでもInterfaceを利用してmixinを実現できます。
pipの呼び出し部分の設計を調べてみた
main関数からどのように機能を呼び出すべきなのか考えています。
参考になりそうな、有名で、かつそんなに難しくなさそうなツールはないかな?と考えていたら思いついたのがpipです。
おそらくPythonで最も有名で、そこそこ高機能だけど、そんなに複雑でなさそうなCLIツール。ぴったりの題材だと思って調べてみました。
ソースコード入手
GitHubにありました。
GitHub - pypa/pip: The Python package installer
エントリーポイントの確認
setup.pyを確認します。
entry_points={
"console_scripts": [
"pip=pip._internal.cli.main:main",
pip._internal.cli.main.pyのmain関数がエントリーポイントだとわかりました。
シーケンス図
エントリーポイントから各機能への呼出しを追いかけて図にしました。
ここでは「pip install」を例として取り上げていますが他の機能も同じ流れです。
正確なUML表記ではありません。関連性が低いMixin関連の親クラスは省略してます。

クラス図
クラス図も作りました。

Commandパターンっぽい
なんとなく予想してましたがCommandパターンっぽいです。
mainがInvoker役、CommandはそのままCommand役、commandsパッケージの各クラスはConcreteCommand兼Receiver役です。
一般的なCommandパターンと異なりConcreteCommandとReceiverが分離していません。ConcreteCommandにはundoやredoがなくrunのみのシンプルな実装でよいので処理詳細をReceiverに移譲するのは過剰だと判断したのかもしれません。もしくはPythonの流儀としてはこれくらいの処理はクラスをExtractせずにやるものなのかもしれません。各機能の見通しはいいと思います。
Template Methodパターンっぽい
最初は気づきませんでしたが、図にして初めて気づきました。CommandクラスとConcreteCommandクラスがTemplate Methodパターンになっています。
Commandクラスの_mainメソッドは以下のようになっています。
def _main(self, args): <環境変数の確認やvirtualenvかどうかのチェックなど> status = self.run(options, args) <Exception処理など>
そしてrunメソッドの実装は以下の通り子クラスに任せています。
def run(self, options, args):
# type: (Values, List[Any]) -> int
raise NotImplementedError
このようにTemplate Methodパターンで機能実行前の環境チェックや実行時に発生したエラー処理などの共通処理を共通化しつつ、機能自体は各ConcreteCommandクラスに委ねています。
routing機能
「list」や「install」などの第1引数を元にどういうルーティングをしているのか気になっていましたが意外にシンプルでした。
pip._internal.commands.__init__.pyに第1引数と対応するConcreteCommandクラス名のテーブルがあります。OrderedDict形式です。
mainは第1引数を元に__init__.pyに問い合わせます。__init__.pyは第1引数に応じたクラス名を取得し、import_moduleやgetattrを使ってインスタンスを作成してmainに返します。mainは取得したインスタンスがなにか意識せずにそのmainメソッドを呼び出します。
循環依存?
cliパッケージとcommandsパッケージの間に循環依存があるように見えます。クラス図 左側の矢印はcliパッケージからcommandsパッケージへ向かい、右側の矢印は逆に向かっています。
私のクラス図の書き方が悪いのかもしれません。
書き方が間違っていない場合、どうして循環しているのでしょう?1つの仮説を立ててみました。Duck Typingです。
Javaならクラス図 左側のmainと__init__の間にInterfaceを作って依存関係を逆転させるところでしょう。Depencency Inversion Principleです。
でもPythonは動的型付け言語なのでInterfaceを明示的に作成する必要がありません。つまりmainと__init__の間にはすでに暗黙のInterfaceが存在し、そのInterfaceには抽象メソッドcreate_commandのみが定義されているのです。
mainは暗黙のうちにこの見えないInterfaceを介して__init__を利用している、いわゆるDuck Typingです。見えないけどすでに依存関係は逆転しているので循環依存は存在しない、、、のかな?自信ありません。
cleancodersのJava Case Studyの(私的)UML図を作った
cleancoders.comというサイトのプログラミング動画を見て勉強しています。 英語で、日本語字幕はなく、高価ですがシニアクラスのプログラマーから直接、教えを受ける機会がない自分には貴重な教材です。
Java Case StudyというシリーズではWebサービスをスクラッチからTDDで開発し、ユースケースを一つ実装するまでを思考錯誤の過程も含めて見せてくれます。 コードはGitHubで公開されています。
GitHub - cleancoders/CleanCodeCaseStudy: Clean Code Case Study
設計やコーディングの進め方、テストの書き方、それらの背景にある考え方、Intellijのちょっとしたテクニックなど独学初心者プログラマには情報の宝庫だと思います。
厄介なのは途中からクラスが増えすぎて、話についていけなくなることです。 最初はついていけるのですが途中からアーキテクチャ変更が始まり、クラスがガラっと入れ替わり、数も増えます。
そこで主要なクラスのみピックアップしてクラス図とシーケンス図を作成しました。 最終形を知っていればなんとかついていけます。
同じ動画を見ている人はいないと思いますが、参考になるアーキテクチャなので投稿します。 個人的なメモ程度なので正規のUMLではありませんがご容赦ください。
クラス図

シーケンス図

感想
- 今回の要件においてはPresenterは過剰設計。将来、他のユースケースで生きてくる?
- UseCaseが複数ある前提ならばfactoryを作ってRouterやControllerに渡してもいい気がする。
- codecastSummariesをDelivery依存なコンポーネントとDelivery非依存なコンポーネントに分割(クラス図の赤線)したのに最終的に同じpackageに入れているのはなぜだろう?
- 同じパッケージだけどJARファイルは分割する?
- codecastSummariesの下にもう1階層パッケージを作って分割する予定だった?
シリーズ概要
- ビジネスロジックを作る
- テスト用の仮Webサーバを自作する
- 最初のユースケースの顧客向けデモを完成させる
- アーキテクチャの変更を行う
- Coverageの確認、Dead Codeの削除を行う
- FailするAcceptance TestをPassさせる
後日談
最近、これが「クリーンアーキテクチャ」と呼ばれるアプリケーションアーキテクチャであることを知りました。ここ数年くらい話題になっていって、iOSアプリ開発で有名なVIPERはクリーンアーキテクチャの亜種だそうです。知りませんでした。
こちらがアーキテクチャ図です。

クリーンアーキテクチャについてはこちらのリンクが最高にわかりやすいです。Javaのサンプルがついているのと筆者の考察が最高です。
実践クリーンアーキテクチャ with Java │ nrslib
クリーンアーキテクチャに関して少し噛み砕かれすぎていますが、アプリケーションアーキテクチャ全体から落とし込んで理解するには最高過ぎるのがこちらです。勉強になる。。。
世界一わかりやすいClean Architecture - nuits.jp blog
Presenterについてようやく理解できた気がします。
Java Case StudyではControllerが入力を受け取り結果を返す役割を担っていました。多くのWebフレームワークはこのように入力を受けたオブジェクトが結果を返す構造になっていると思います。このような環境においてはOuput Boundary/Presenterは無理やりねじ込んだ感がいなめませんでした。
一方、アーキテクチャ図を見るとControllerは入力を受け取るだけで結果の処理には関与していません。Presenterが直接、結果を返しています。このように入力を受けたオブジェクトと結果を返すオブジェクトを分離できるフレームワークもあります。このような環境においてはInput Boundaryと対をなすOutput Boundary/Presenterという抽象化レイヤは意味があると感じます。
ではなぜJava Case StudyではOuput Boundary/Presenterをねじ込んでいるのか?想像するにUseCase Interactorをどちらのフレームワークにも対応できる、フレームワーク非依存な構造にするためだと思います。これならフレームワークを引っ越ししてもControllerとPresenter部分だけ書き換えれば済みます。このアーキテクチャにおいて最も重要なUseCase Interactorは影響を受けません。
さらに想像すると、このJava Case Studyシリーズは「Presenterを省略するな!ControllerとPresenterで協調してうまくやれ!」というメッセージなのかと思いました。(省略する気だった人)
f-stringの使い型
f-stringはPython 3.6から導入された文字列のフォーマットを制御する方法の1つです。
+で文字列リテラルと文字列変数を結合したり、str.format()を使うよりもコードがすっきりします。
基本
- 文字列をf''で囲う
- 変数と置き換えたいときは{変数名}とする
name = 'john'
f'Hello {name}'
折り返し
長い文字列を記述していると折り返したくなります。
そういうときはエディタで改行して行末に\(バックスラッシュ)を付けます。
long_message = f'\
this is a very long message,\
and it's followed by another long message.\
{author}
’
{}を使いたいとき
JSON文字列を記述するときは{}(中括弧)を使います。
しかし中括弧はf-stringでは置換フィールドと解釈されます。その上、中括弧はバックスラッシュではエスケープできません。
f-stringでは中括弧を以下のように2重中括弧({{)でエスケープします。
json_str = f'{{\
"sushi": "{sushi_recipe}",\
"curry": "{curry_recipe}"\
}}’
これで長いJSON文字列もすっきり書くことができます。