Ansibleの基礎
- 歴史
- 概要
- 構成
- 基本的な使い方
- 変数
- 変数(外部ファイル)
- 変数(groupごとに定義)
- 変数(hostごとに定義)
- 繰り返し処理
- 条件分岐
- 出力結果を保存
- 結果結果を整形して保存
- Advancedな使い方
- 推奨構成
DevOpsやCI/CDの中核にあるのが自動化である。あらゆる場面において作業を自動化することが推奨される。
従来はインフラ屋さんが手動で実施していたインフラ設定作業も自動化の対象に含まれる。
インフラ設定管理を自動化するためのツールが設定管理ツールであり、その中で今、最も人気があるのがAnsibleだ。
ここではAnsibleについてみていこう。
歴史
chef、puppetなどに比べると構成管理ツールとしては比較的新しい。
概要
基本設計理念
- Immutable Infrastracture
- 冪等性の担保
- 各モジュールがそれぞれの方法で冪等性をチェックしてる
製品(OSS)
製品(有償)
Dry-run機能
- check
- 変更を加えない処理を実施
- diff
- ファイルの変更を確認
Orchestration機能
- アプリケーションのデプロイのこと
- 複数の手順を順序通りに実行してアプリケーションをデプロイすることができる
- スケールアウトはInventoryに追加するだけで実施できる
機器、ベンダごとのモジュールが必要
- ベンダ間の差異は抽象化はされていない
- NAPALMとは思想が異なる
構成
module
- taskの中で利用できる指示の集まり
- デバイスごとに異なる
- コレクションとして管理・入るされている
task
- 処理
play
- taskの集まり
playbook
- playの集まり
- YAML形式で記述
- 以下のキーワードから構成される
- name
- hosts
- vars
- tasks
inventory
- taskの対象となるhostを定義したファイル
- 実行時に-iオプションで指定する
- 指定されなかった場合はデフォルトでは/etc/ansible/hostsを探す
基本的な使い方
実行方法
ansibleコマンド
- adhoc実行するためのコマンド
-mでモジュール指定- 指定しなければ
ansible.builtin.command
- 指定しなければ
-aでモジュールへの引数指定
ansible-playbookコマンド
- playbookを実行するコマンド
-i:インベントリファイル-v:デバッグ
変数
varsでplaybook内に変数を定義- {{ 変数名 }}で参照
変数(外部ファイル)
vars_filesで外部ファイルに変数を定義して呼び出せる
変数(groupごとに定義)
- group_vars/に<group名>.yml
変数(hostごとに定義)
- host_vars/に<host名>.yml
- inventoryファイルに直接記載することもできる
繰り返し処理
- 基本的には
loopを使う with_<plugin>でもできるuntilはシステムが特定の状態になるまで待機するときに使える
条件分岐
whenを使う
出力結果を保存
- 結果を返す処理を実行
registerで結果を変数へ格納local_acion: copyで変数をファイルへ出力
結果結果を整形して保存
registerした変数をset_factでホスト変数へtemplateでホスト変数を整形してファイル化
Advancedな使い方
taskをモジュール化する
- roleはtaskをモジュール化したもの
- rolesフォルダに作成する
ansible-galaxyコマンドでひな形を作成できる
- 呼び出し方は3種類ある
rolesinclude_roleimport_role
複雑な処理を実施したい
ネットワーク機器を管理する
- localhostで実行する
- gather_factsはno
- ネットワーク機器ではなくLocal PCの情報を集めてしまう
推奨構成
一般的な環境
production # inventory file for production servers
staging # inventory file for staging environment
group_vars/
group1.yml # here we assign variables to particular groups
group2.yml
host_vars/
hostname1.yml # here we assign variables to particular systems
hostname2.yml
library/ # if any custom modules, put them here (optional)
module_utils/ # if any custom module_utils to support modules, put them here (optional)
filter_plugins/ # if any custom filter plugins, put them here (optional)
site.yml # master playbook
webservers.yml # playbook for webserver tier
dbservers.yml # playbook for dbserver tier
roles/
common/
webtier/
monitoring/
productionとstagingで共通する変数が少ない場合
inventories/
production/
hosts # inventory file for production servers
group_vars/
group1.yml # here we assign variables to particular groups
group2.yml
host_vars/
hostname1.yml # here we assign variables to particular systems
hostname2.yml
staging/
hosts # inventory file for staging environment
group_vars/
group1.yml # here we assign variables to particular groups
group2.yml
host_vars/
stagehost1.yml # here we assign variables to particular systems
stagehost2.yml
library/
module_utils/
filter_plugins/
site.yml
webservers.yml
dbservers.yml
roles/
common/
webtier/
monitoring/
SeleniumをPythonで使う
Seleniumとは
Web ScrapingやWeb UIのテストで利用するブラウザ操作自動化ツールです。
Java、Python、C#、Ruby、JavaScript、Kotlinなどの言語で利用できます。
今回はPythonで利用します。
基本的にはテスト自動化ツール
基本的にはテスト自動化ツールと考えた方がよいです。
勘違いしてはいけないのは既存手動業務(Webサーバへの入力作業)を全自動化するためのツールとしては必ずしも最適ではないということです。
そのような複雑な自動化はWeb APIを使った方が確実ですし、安定性や性能面でも優れたものになるはずです。
Seleniumはきれいに動くこともあればきれいに動かないこともあります。
原因はWebページのDOM構造だったり、Selenium自体の仕様や問題だったりします。
単純なWeb Scrapingなら問題ないことが多いですが、はまるときは本当にはまるので注意してください。
準備
必要なものはchromedriverとseleniumです。
chromedriverはMacならhomebrewでインストールできます。
brew install chromedriver
次にseleniumをpip/pipenvでインストールしましょう。
pip install selenium
Hello World
とりあえず動かしてみましょう。
Selenium公式サイトにあるサンプルです。
import time
from selenium import webdriver
driver = webdriver.Chrome()
driver.get("http://selenium.dev")
time.sleep(5)
driver.quit()
環境のセットアップが完了していればコピペで動きます。
実行するとChromeブラウザが起動し、公式サイトにアクセスし、5秒後にブラウザが終了します。
基本的な操作
以下に基本的な操作の方法を紹介します。
文字を取得
message_element = driver.find_element(by=By.ID, value='message') print(message_element.text)
- 前提条件として
Byをimportする必要がある
from selenium.webdriver.common.by import By
文字を入力
- 先程と同じ方法で文字列入力フィールドのエレメントを取得
send_keysメソッドでテキストを送る
text_field_element = driver.find_element(by=By.ID, value='text')
text_field_element.send_keys('some text')
ボタンをクリック
- 先程と同じ方法でボタンのエレメントを取得
clickメソッドで押す
button = self.browser.find_element(by=By.ID, value='button') button.click()
エレメントが表示されるまで待つ
- 特定のエレメントが表示されるまで待つことができる
- ページの読み込み・表示が遅いときに有効
- 下の例ではid=messageのエレメントが見つかるまで最大60秒間待つ
portal_name_node = WebDriverWait(driver, 60).until(
EC.visibility_of_element_located((By.ID, 'message')))
- 前提条件として
WebDriverWaitをimportする必要がある
from selenium.webdriver.support.ui import WebDriverWait
iframeへアクセス
- iframeの中へアクセスする場合はiframeのエレメントを取得してswitch_toする
iframe = driver.find_element(by=By.TAG_NAME, value='iframe') driver.switch_to.frame(iframe)
Shadow DOMへアクセス
- Shadow DOMは他のDOMから独立したTreeを作成する技術
- Shadow DOMにアクセスする場合はShadow DOMのエレメントを取得してshadow_rootを取得する
shadow_dom = driver.find_element(by=By.ID, value='foo') root = shadow_dom.shadow_root
Python終了時にChromeを閉じない
options = Options()
options.add_experimental_option('detach', True)
driver = webdriver.Chrome(options=options)
- 前提条件として
Optionsのimportが必要
from selenium.webdriver.chrome.options import Options
試験作成時の注意点
公式に色々と有益な情報があります。
https://www.selenium.dev/documentation/test_practices/
ここでは一部のみご紹介します。
Page Objectパターンを使う
- DOMアクセス処理をテストコードから排除しPage Objectへ集中させる
- DOM構造が変化した場合でもテストコードは影響を受けない
Fluent APIを使う
- Page Objectのメソッドは次のPage Objectを返す
- メソッドチェーンするときれいに見える
Fluent APIを使わない場合
signin_page.login(username, password)
home_page = HomePage()
home_page.go_to_profile_page()
profile = Profile()
profile.change_name('new name')
Fluent APIを使った場合
signin_page.login(username, password).go_to_profile_page().change_name('new name')
Seleniumでログインしない
force-aloha-pageの苦労話
SalesforceのあるアプリがSeleniumで読めたり、読めなかったりと挙動が不安定でした。
色々と調査した結果、以下のことがわかりました。
- force-aloha-pageタグがShadow DOM
- Shadow DOMのすぐ下にiframeがある
iframeにはすぐ気づきましたがforce-aloha-pageがShadow DOMであることに気づけず時間を無駄にしました。
そこに気づけば対処はシンプルです。
- force-aloha-pageタグのshadow_rootを取得
- shadow_rootを利用してiframeのエレメントを取得
- iframeのエレメントへswitch_to
ここまで進んだところでiframeの中が表示されるのにかなり時間がかかることがわかりました。
iframeにswtich_toした後にiframe内のエレメントにアクセスしようとすると例外がガンガン発生します。
苦肉の策としてiframe内のエレメントに最初にアクセスするところで数回Retryさせることにしました。
また、IDがLocatorとして使えないケースが多く、XPATHを多用することになりました。
簡単なPython配布パッケージの作り方
Pythonで書いたコードを利用するときどうしますか?
一番簡単な方法はpythonコマンドの引数として実行することでしょう。
python mycode.py
でも実行するたびにコードがあるフォルダに移動したり、逆に実行したいフォルダにコードをコピーしたり、もしくはコードがあるフォルダの長い絶対パスを書いたりするのって面倒じゃないですか?
また、もしコードが複数のモジュールで構成されていた場合はどうしましょう?複数のコードをコピーするのは煩雑です。エイリアス、リンク、PATHを活用すれば対処できそうですが、もっとよい方法はないものでしょうか?
ライブラリとして利用するならどうしましょう?開発環境にコピーしてimportしますか?面倒ですしコピーが沢山生まれて管理できなくなりませんか?
配布パッケージ
そんなときは配布パッケージにしてpipでインストールしましょう。そうすれば一般的なツールやライブラリのように利用できます。
また、作成したコードの配布、デプロイを意識することは開発者としてとてもよい勉強になります。是非、体験することをおすすめします。
作成方法
Pythonでは配布パッケージの種類も作り方も色々あります。
ここではPyCharmを活用した、追加のツールのインストールが不要な、シンプルな方法をご紹介します。pipとPyCharm CEがインストールされている前提ですがそれ以外は必須ではありません。
パッケージを広く公開したいならもっと色々と調べた方がよいですが、さくっと自分用パッケージを作って試したい人にはこれでも十分楽しめるはずです。
1. コードを書く
以下のような構成のコードを想定します。
mypkg
├── mypkg
│ ├── __init__.py
│ └── main.py
└── tests
└── test_main.py
main.pyにはmain関数が定義されているとします。
2. setup.pyを作成する
以前はPyCharmの「Tools」から「Create setup.py」を選択して雛形を作成してから編集していましたがやめました。PyCharmが作成した雛形はdistutils.coreを使っていたり、修正する箇所が多く、もはやあまり意味がないと思ったからです。
- 以下の内容をベースに最上位階層にsetup.pyを作成する。
from setuptools import setup
setup(
name='mypkg',
version='0.0.1',
packages=['mypkg'],
license='MIT',
author='myname',
install_requires=[
"selenium==4.1.2",
],
entry_points={
'console_scripts': [
'mypkg=mypkg.main:main',
],
},
description='Some description'
)
- 足りない項目の追加、不要な項目の削除を行う。
- 編集する上での注意点は下記3点。
packagesにテスト用のパッケージがないことを確認する
- テストまで配布されてしまう。
依存パッケージがあればinstall_requiresを定義
- 依存パッケージをinstall_requiresに書いておくとpip installするときに自動でインストールしてくれる。
- 以前はバージョン指定ができなかったそうだが今日時点では指定できる
- 依存パッケージがなければinstall_requiresは削除する
コマンドにするならentry_pointsを定義
3. パッケージの挙動を確認
- PyCharmのTerminalからインストールしてパッケージの挙動を確認する
cd <setup.pyがあるフォルダ> pip install -e .
-eを指定すると開発環境のコードからリンクが張られた形になる- 下記のように
pipenvを使ってインストールすると開発環境のPipfileが更新されてしまうので注意- 開発対象パッケージが開発対象パッケージ自身に依存しているっておかしいですよね?
pipenv install -e .
4. 配布用のパッケージを作成
PyCharm → Tools → Run setup.py Task... → sdist
- distフォルダが作成され、中にtar.gz形式のパッケージが配置される
bdist wheelでもよい- sdistの中身はソース, bdistの中身はバイナリ
5. 配布パッケージを仮想環境で試す(Option)
pipenvの場合
- mkdir <適当なフォルダ>
- cd <適当なフォルダ>
- pipenv --python 3.9
- pipenv install <配布パッケージ>
- pipenv shell
- 動作確認
- deacitvate
- exit
- pipenv --rm
- cd ..
- rm -rf <適当なフォルダ>
virtualenvの場合
- mkdir <適当なフォルダ>
- cd <適当なフォルダ>
- virtualenv <仮想環境名>
- source <仮想環境名>/bin/activate
- pip install <配布パッケージ>
- 動作確認
- deacitvate
- rm -rf <適当なフォルダ>
6. pipで管理
これでpipで管理できるようになりました。後は普通にpipで管理してください。
レポジトリがあれば登録しましょう。レポジトリがない場合はローカルPCの自作パッケージフォルダにまとめておいて、インストールするときは以下のようにするのがよいと思います。
pip install --find-links <自作パッケージフォルダ> <配布パッケージ>
これでリポジトリではなくローカルPCの自作パッケージフォルダを探してインストールしてくれます。
この時点で動かないことが発覚したり、ツールが不要になったりして依存ライブラリごとまとめて削除したくなることもるでしょう。そのようなときはpip-autoremoveを使うと便利です。
以下の方法でインストールします。
pip install pip-autoremove
削除するときは以下のようにします。
pip-autoremove <パッケージ名>
削除対象パッケージと依存ライブラリが表示されます。他のパッケージが依存しているライブラリは除外してくれるそうですが念の為に確認した方がよいでしょう。問題なければ「Y」を押して削除を実行します。
付録
最後にパッケージ、モジュールの状態を確認するときに便利なPython機能をいくつか紹介します。
sys.modules
- load済みのモジュール名とモジュールのマップ。
- loadされていても意図したnamespaceにimportされているとは限らない
- 確認するときはsorted(sys.modules)でソートしたキー配列を取得した方が見やすい。
>>> for i in sorted(sys.modules): ... print(i) ...
help('modules')
- ロード可能なモジュールの一覧を表示する。
- current directoryにあるモジュールも表示されるので混乱しないこと。
sys.path
- importするモジュールを探すパス。
- ここにパスが登録されていないとモジュールを見つけることができない
os.getcwd()
- current directoryを表示
SSH接続の近代化 - 公開鍵認証 + コマンド入力簡略化 + 踏み台サーバ対応
目的
自分のPCからSSH接続する機会自体少ないので困ってることはありませんが、環境が旧世代的な感じがしたので改善することにしました。
まず最近、廃れ気味なパスワード認証をやめて公開鍵認証方式に統一します。
踏み台サーバを経由した多段接続では今までSSHコマンドを2度実行していましたが1度で済むように変更します。
さらにコマンド入力がssh <色々なオプション> <ユーザ名>@<ホスト名 >のように長くならないよう.ssh/configで簡略化します。
1. 公開鍵方式導入
鍵作成
ローカルPCで公開鍵と秘密鍵を作成します。
鍵の作成にはssh-keygenコマンドを使います。
色々とオプションを指定できますが、今回はすべてデフォルトです。
SSH接続時に入力ゼロでログインできるよう、passphraseは空にします。
% cd ~/ % ssh-keygen Generating public/private rsa key pair. Enter file in which to save the key (/Users/hoge/.ssh/id_rsa): Enter passphrase (empty for no passphrase): Enter same passphrase again: Your identification has been saved in /Users/hoge/.ssh/id_rsa Your public key has been saved in /Users/hoge/.ssh/id_rsa.pub The key fingerprint is: SHA256:<変な文字列> hoge@<マシン名> The key's randomart image is: +---[RSA 3072]----+ <変なアスキーアート> +----[SHA256]-----+ %
.ssh/にid_rsaとid_rsa.pubが作成されます。
% ls .ssh id_rsa id_rsa.pub known_hosts
known_hostsは前からあったものなので無視してください。
id_rsaが秘密鍵、id_rsa.pubが公開鍵です。
秘密鍵が漏洩しなければ公開鍵は長期間、使い回すことができます。
鍵管理が完璧ならssh-key-genは滅多に実施する必要がない作業です。
公開鍵を接続するホストへ配置
作成した公開鍵を接続先のホストへSCP等で転送します。
もし接続先ホストに~.sshや~.ssh/authorized_keysがない場合は作成します。
このときPermissionに気をつけましょう。
~.sshは700~.ssh/authorized_keysは600
[user1@host1]$ install -m 0700 -d ~/.ssh [user1@host1]$ touch ~/.ssh/authorized_keys [user1@host1]$ chmod 600 .ssh/authorized_keys
接続先ホストの~.ssh/authorized_keysにローカルPCから転送した公開鍵を追記します。
[user1@host1]$ cat id_rsa.pub >> .ssh/authorized_keys
公開鍵認証の動作確認
準備は完了です。
接続してみましょう。
% ssh user1@192.168.1.1 Last login: Fri May 20 15:19:30 2022 from 192.168.1.2 [user1@host1]$
成功です!
パスワードなしで接続することができました。
近代化への大きな一歩です!
2. コマンド入力簡略化
便利になりましたがssh user1@192.168.1.1ってタイプするの少し面倒ですね。
もっと入力を短く済ませることができます。
ローカルPCで~/.ssh/configを作成し以下のように記述します。
Host host1 HostName 192.168.1.1 User user1
これでssh host1とするとssh user1@192.168.1.1と同じになります。
早速、試してみましょう。
% ssh host1 Last login: Fri May 20 16:38:31 2022 from 192.168.1.2 [user1@host1]$
入力は短くなりましたが同じように接続先ホストへ入ることができました。
3. 踏み台サーバ対応
最後に踏み台サーバを介した遠隔サーバへの多段SSH接続に対応します。
先程のhost1(192.168.1.1)が踏み台サーバで、その先に遠隔サーバ remote1(172.16.1.1)がいると想定します。
今までは最初にローカルPCからhost1へ、次にhost1からremote1へ接続するためにSSHコマンドを2回入力していました。
これが一撃で完結するように変更します。
遠隔サーバへ公開鍵を配置
先程、作成した公開鍵を同じ手順で遠隔サーバにも配置します。
動作確認
ProxyCommandの前提条件が満たされたか動作確認を実施します。
ローカルPCで以下のコマンドを投入します。
% ssh -o ProxyCommand="ssh -W %h:%p host1" foo@172.16.1.1 Last login: Fri May 20 15:19:36 2022 from 172.16.1.2 [foo@remote1]$
ProxyCommandでプロキシ設定をしています。
%hと%pは実行時に自動でIPアドレスとポート番号に置換されます。
host1が.ssh/configに設定されている前提です。
一発でローカルPCからhost1の先のremote1(172.16.1.1)へ接続できました。
~/.ssh/config編集
ローカルPCで~/.ssh/configを開いて以下の内容を追記します。
Host remote1 HostName 172.16.1.1 User foo ProxyCommand ssh -W %h:%p host1
動作確認
動作確認します。
% ssh remote1 Last login: Fri May 20 16:57:26 2022 from 172.16.1.1 [foo@remote1]$
ssh remote1だけでローカルPCからhost1の先のremote1へ接続できました。
結論
パスワード認証を廃して公開鍵認証方式に統一しました。 これだけでもかなり「旧世代」感を払拭できました。 一度、鍵を作成してしまえば新しい接続先を追加するのも簡単です。
またSSHのProxyCommandを利用して踏み台サーバを介した遠隔サーバへの接続手順を簡素化しました。 同じことを繰り返す馬鹿っぽさが軽減されたと思います。 遠隔サーバにSCPでファイル転送をするときには大きなメリットを感じました。
加えて.ssh/configを利用してコマンド入力を短縮しました。
より安全に、効率的に、(一見)スマートになりました。 また、ここまで実施しておくとAnsibleなどSSH接続を利用するツールを導入するときもスムーズです。 今後、新しい接続先が増えたときも同じようにしていきたいと思います。
テスト駆動開発(TDD)のコーディングの流れ
初学者がTDDでコーディングするとき疑問に思うことは多々あります。
「次はどんな試験書けばいいんだっけ?」
「この試験はどんなコードでパスさせるのが正解なんだろう?」
そこでTDDでコーディングする基本的な流れをまとめてみました。
(久し振りにTDDしたら色々忘れてたので備忘録として残しておきます)
1. オブジェクトが持つ機能をイメージする
まずはこれから書くオブジェクトの機能をイメージします。
ある程度、全体像がわからないと試験戦略をたてることができません。

2. 機能を3つのグループに分類
思いついた機能を以下の3つのグループに分類します。
- コア機能
- コアに依存しない機能、もしくはコアが依存する機能
- コアに依存する機能
特に重要なのは1と2です。
3は後から考えてもOKです。

3. 各グループを順に試験・実装
各グループを以下の順番で試験・実装します。
- コアに依存しない機能、もしくはコアが依存する機能
- コア機能
- コアに依存する機能

4. 各機能は下記の順に試験
各グループの機能を試験・実装するときに留意したい点があります。
各機能は下記の順に試験しましょう。

5. 優先順位に従って実装
試験を書いたら次はその試験をパスさせるコードを書きます。
コードを書くときは下記の優先順位に従い実装しましょう。

以上が基本の流れです。
細かい発展的な部分で感じていることもありますがまだ確信が持てていません。
いずれそれも整理、文書化できたらいいなと思います。
IntelliJ IDEA + JUnit5のTDD環境セットアップ
IDEを起動してから最低限のTDD環境を整えるまでの手順を記します。
IntelliJ IDEAとJUnit5が前提です。
(久々にJavaを触ったら色々と忘れてたので備忘録として残しておきます)
手順
IntelliJ IDEAでプロジェクトを作成
テストクラスを新規作成
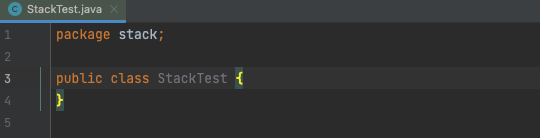
- 空のテストメソッドを作る
- Live Templateを利用して「test+<TABキー>」で作成している
- Live Templateについてはこちらを参照。
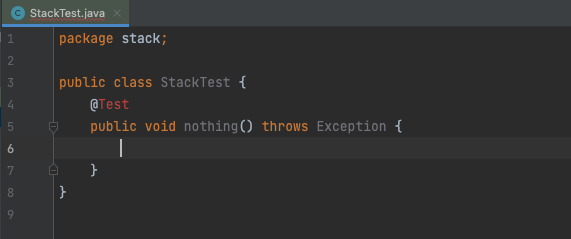
- エラーが出ている@Testアノテーションのコンテキストメニューからorg.junit.jupiter.api.TestをImportする

- assertXXXメソッドについてもコンテキストメニューを使ってorg.junit.jupiter.api.Assertionsからstatic importする
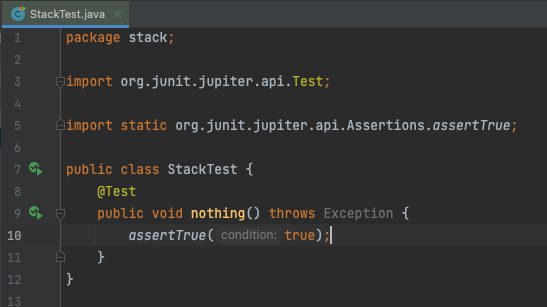
テストコードのインスペクション規則変更
- この状態だと「throws Exception」節で警告が出る

無害だが重要な警告を見落とす原因にもなるので対処したい
メニューバーの「コード」から「コードのインスペクション」を選択
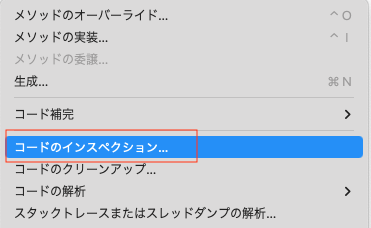
- 「Project Default」が選択されていることを確認し「構成」を押下
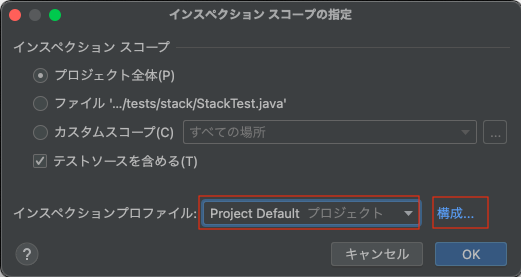
- 「Java→宣言の冗長性→冗長な'thows'節」で「テスト」のチェックを外す
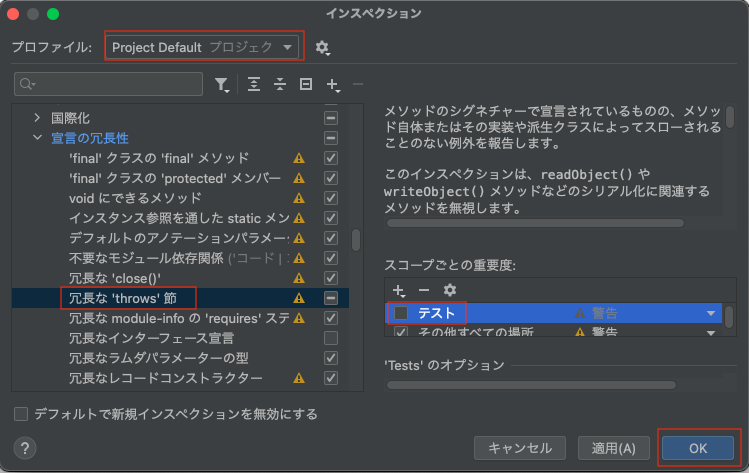
その他
例外の試験はassertThrowsを使う
非staticなinner classに@Nestedアノテーションを付与するとinner class内で試験できる
Terraformの特性を知る
Terraformは優れたツールだ。
Ansibleにはない、純粋な宣言型の振る舞いを経験するとある種の感動を覚える。
しかし使い込んでいくとわかるが癖がある。
ツールを使いこなすにはそのツールの背景にある思想、設計、そして癖を理解することが重要だ。
ここではそういったことをいくつか簡単に紹介したい。
Terraformの基礎についてはこちらの投稿で説明した。必要に応じて参照して欲しい。
Terraform全般
純粋な宣言型
- Terraformの最大の特徴は宣言型であること
- 例えばリソースA、Bを作成したとする。
- リソースBが不要になったら宣言ファイルからBを削除して再度、applyすればAだけ残る
- AnsibleであればBを削除するPlaybookを作成する必要があるがTerraformでは不要だ
- 管理対象システムの変更が頻繁に発生する場合、工数削減が期待できる
インフラの細部までは管理できないことがある
- Terraformは制御対象システムの細部まで管理することを目的としていない
Terraform is not intended to give low-level programmatic access to providers, but instead provides a high level syntax for describing how cloud resources and services should be created, provisioned, and combined. 出典:https://www.terraform.io/intro/vs/boto
- 実際できるケースは少なくないが、できないからといって騒いでも改善される可能性は低い
- 細かい制御が必要なケースは他のツールに任せることになる
設定ファイル関連
進化が激しい
- 年々、便利な機能が追加され、過去の制約がなくなり、以前は必要だった小技が不要になっている
- 1年前の情報は信じず、時間はかかるが公式ドキュメントで地道に勉強することが望ましい
汎用プログラミング言語ほど柔軟な制御構造を持たない
- HCLは一見、柔軟な言語に見える
- 設定ファイル記述言語としては便利だが過度な期待は禁物だ
- 例えばLoop機能はあるが任意の範囲の処理を繰り返すような使い方はできない
count、for_each- これらは厳密にはresource、moduleの複製回数を指定する機能
- Loopを利用してif文的なConditionも実現できるがLoop同様、resource、module単位での条件分岐になる
- 任意の範囲の処理を条件分岐するような使い方はできない
resource XXX "this" {
count = var.some_flag ? 1 : 0
:
}
- ネストされたLoop、Conditionはいずれも苦手だ
- データ構造をフラットにして1ループに収まるよう工夫する
制御対象システムに対する深い知識が必要
- 制御対象システムに対する理解がないと設定ファイルが書けない
- Terraform RegistryのProvider Documentの中から適切なresourceを探せない
- resourceの各argumentの意味と使い方を理解できない
- apply後、正しい設定が投入できたか調査できない
- 問題発生時に管理対象システムをデバッグできない
- Terraform自体は実はかなりシンプルで、Providerや制御対象に対する理解度の方が重要
module compositionの階層は2〜3くらいが推奨
- moduleから他のmoduleを利用できる
module compositionと呼ばれている
- 呼び出しの階層が深すぎると可読性が落ちる
- 2階層以内が推奨
- 最大でも3階層に収める
循環依存に注意
- 呼び出しがmodule間で循環すると
terraform planでエラーが発生し、terraform applyが実行できなくなる - module間の呼び出しは便利で推奨されているが循環しないように注意が必要
- 循環した場合はmoduleを分割する
- 分割が進んでいくと小粒なモジュール同士の実行順序をどう制御するかという課題が生まれる
- terragrunt、terrafileなどのOSSが視野に入ってくる
- 分割が進んでいくと小粒なモジュール同士の実行順序をどう制御するかという課題が生まれる
Listは注意
- Listのデータをもとにリソースを作成した場合、TerraformはList内の順序を覚えている
- List内の順序が変わるとTerraformは設定がなくなったと勘違いして設定の削除、再作成を行う
- Map、Setを使った場合は起こらない
State関連
版数管理する
- versioning機能があるbackendを使うこと
- 作業履歴になる
- 問題があった場合に戻れる
- Gitは後述するロック機能がないので注意
plan/apply時はロックする
- ロック機能があるbackendを使うこと
大きくなったら分割する
- 大きくなるとplan/applyに時間がかかる
- ロック時間が長くなるとチーム全体の生産性に影響する
- 適切な単位に分割した方がよい
Terraform以外から投入した設定を残したい場合
- 以下の選択肢がある
- Stateの内容と干渉しないのならば無視することができる
- 干渉する場合、
terraform importでTerraformの管理化に組み込める- 面倒なので定常業務として実施するのは厳しい
- Terraformを導入した場合、Terraform以外から設定を投入することはやめた方がよい
構造
envsとmodulesを分ける
- 1つのディレクトリにすべての設定ファイルを集めると柔軟性、管理性、安全性が損なわれる
- 環境ごとの情報をenvsに配置する
- 各環境が共通的に利用するmoduleをmodulesに配置する
sample_project
├── envs
│ ├── production
│ │ ├── locals.tf.txt
│ │ ├── main.tf.txt
│ │ ├── outputs.tf.txt
│ │ ├── provider.tf.txt
│ │ └── version.tf.txt
│ └── staging
│ ├── locals.tf.txt
│ ├── main.tf.txt
│ ├── outputs.tf.txt
│ ├── provider.tf.txt
│ └── version.tf.txt
└── modules
├── module_A
│ ├── main.tf.txt
│ ├── outputs.tf.txt
│ └── variables.tf.txt
└── module_B
├── main.tf.txt
├── outputs.tf.txt
└── variables.tf.txt